Bistu Library API
北京信息科技大学图书馆API。(PHP语言实现)
思路:
1.post数据,分析网页url。
2.加壳。
说说大概过程,首先登陆图书馆主页,进入图书检索页面:
http://211.68.37.131/book/queryIn.jsp
提交查询数据,用chrome或Firefox等开发工具抓取到post数据包,分析之,如本校图书检索,提交检索词之后跳到新页面(http://211.68.37.131/book/queryOut.jsp)。表面上看不出post地址,抓包也看不出提交地址:
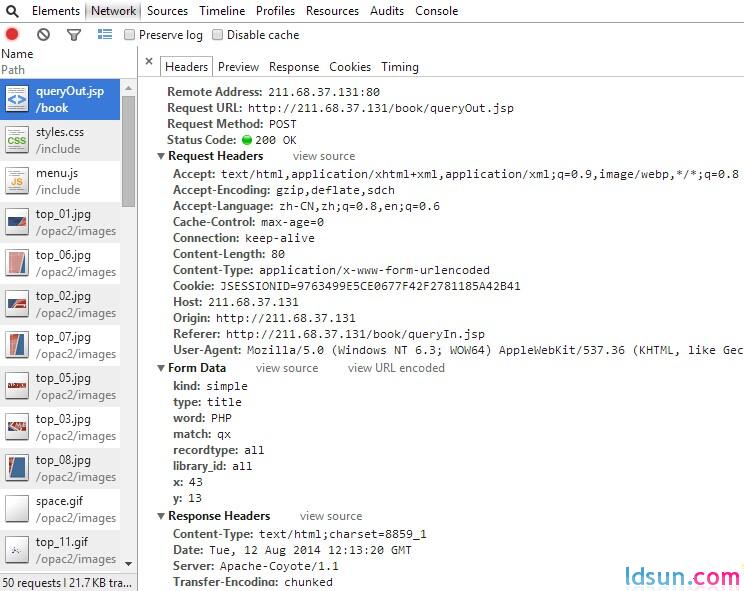
但区区方正系统怎么能难倒聪明的大家呢,对搜索结果的页面:
(http://211.68.37.131/book/queryOut.jsp)分析,不难发现,search result实则是iframe框架:
iframe src=’search.jsp?recordtype=all&library_id=all&kind=simple&word=PHP&cmatch=qx&searchtimes=1&type=title’ name=”ivote” id=”ss1” frameborder=0 width=”990” height=”450” style=”overflow:hidden”
取数据就跟看人一样。一眼看上去没啥,还不错。但等你细心去观察它,去测试它,它就马上原形毕露,将本质暴露出来:
search.jsp?recordtype=all&library_id=all&kind=simple&word=PHP&cmatch=qx&searchtimes=1&type=title
主要参数说明:
recordtype:资料类型,默认为all
library_id:分馆名称,默认为all
kind: 隐藏字段,默认为simple
word:检索词,必填
cmatch:匹配方式,默认为qx
searchtimes:默认为1
type:检索词类型,默认为title
post之后获取到的是默认的前10条数据,怎么破?easy,直接请求post的url页面
(http://211.68.37.131/book/search.jsp?recordtype=all&library_id=all&kind=simple
&word=PHP&cmatch=qx&searchtimes=1&type=title),再分析之:

你会发现,你会流泪,真正…….好吧,我走神了。。。你会发现size参数,测试下,在url后直接加上&size=50,发现数据增加到50条。OK,这样算是有API了。
我的初衷是做微信查图书的功能。所以还需改造一番,比如取到数据后,还需取到图书的详细信息(在架?可借?等),其详细信息在图书title的link中,正则出来即可,然后再取到详细信息。
整体流程:user post data -> get search result -> print/get link ->get book info ->print
效果图如下:
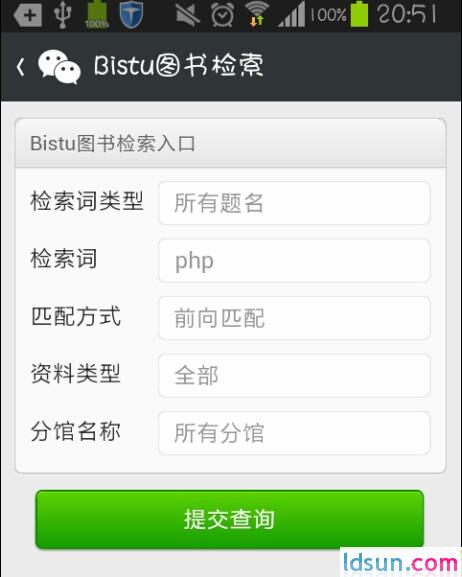
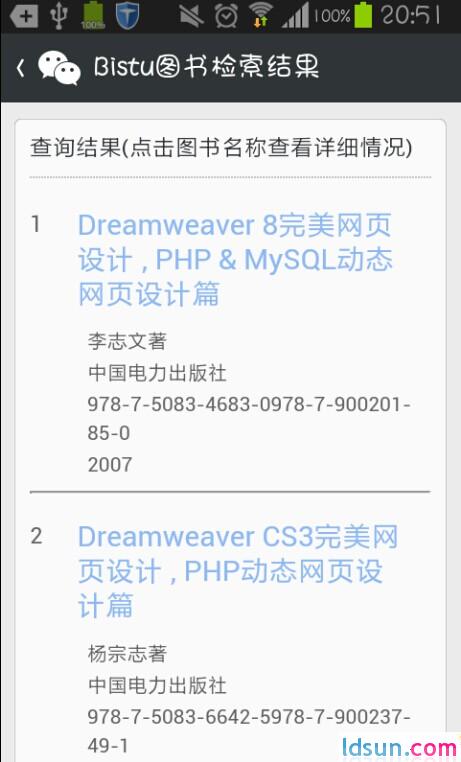
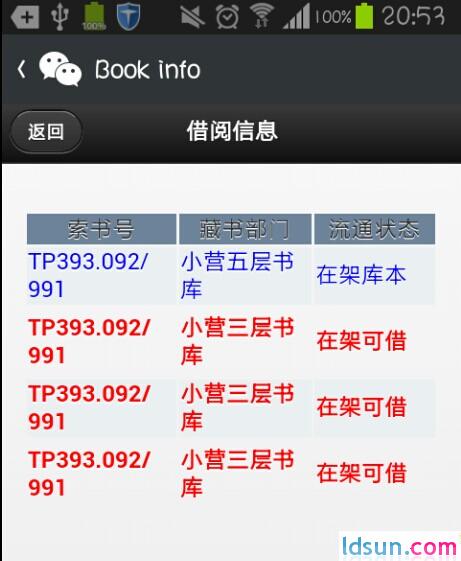
可通过关注服务号【bistu】查看。

代码已提交之github:https://github.com/flute/Bistu-library-API
欢迎交流学习。
Bistu Library API

