use
target url:https://cnodejs.org/
cd nodejs
mkdir test && cd test
touch node.js
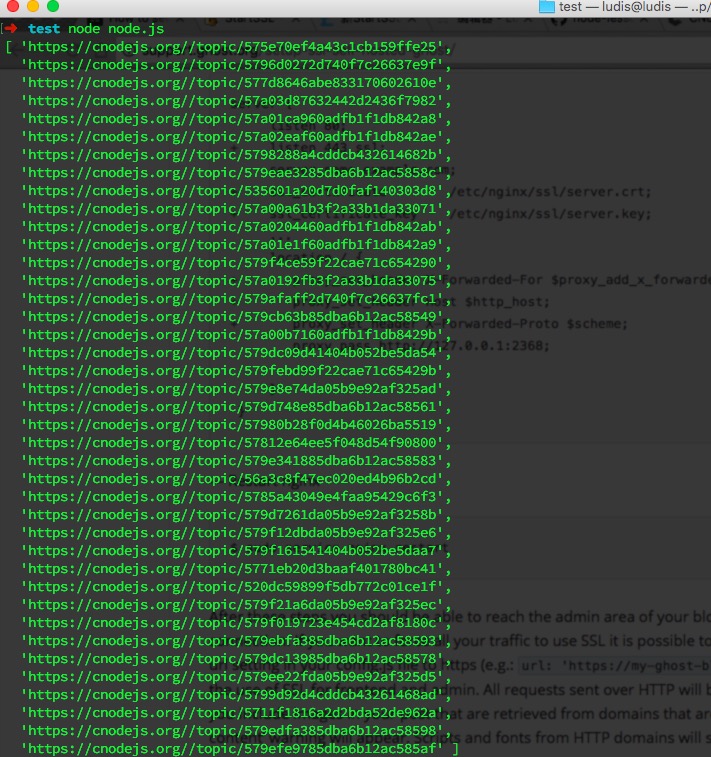
抓取其首页数据,共40篇文章。
- 首先爬取首页篇文章的URL,将得到的40篇文章的URL存入数组articleUrlArr
- 然后爬取每篇文章的详细内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| var eventproxy = require('eventproxy');
var superagent = require('superagent');
var cheerio = require('cheerio');
var articleUrlArr = [],
baseUrl = 'https://cnodejs.org/';
superagent.get(baseUrl).end(function(err, res) {
if (err) {
console.log(err);
}
var $ = cheerio.load(res.text);
$('#topic_list .topic_title').each(function(idx, elements) {
var href = baseUrl+elements.attribs.href;
articleUrlArr.push(href);
});
console.log(articleUrlArr);
});
|
https://ludis-1252396698.cos.ap-beijing.myqcloud.com/ludis/nodejs.png
然后再分别爬取40篇文章的详细内容,即发出40个并发请求,同时爬取数据,调用eventproxy 的 #after API。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| articleUrlArr.forEach(function (url) {
superagent.get(url).end(function (err, res) {
console.log('fetch ' + url + ' successful');
ep.emit('task', [url, res.text]);
});
});
ep.after('task', articleUrlArr.length, function (data) {
data = data.map(function (topicPair) {
var url = topicPair[0];
var html = topicPair[1];
var $ = cheerio.load(html);
return ({
title: $('.topic_full_title').text().trim(),
href: url,
comment1: $('.reply_content').eq(0).text().trim(),
});
});
console.log('final:');
console.log(data);
});
|

