PHP抓取静态页面源码及资源并保存
这是一个可以获取网页的html代码以及css,js,font和img资源的小工具,主要用来快速获取模板。如果你来不及设计UI或者看到不错的模板,则可以使用这个工具来抓取网页和提取资源文件。提取的内容会按相对路径来保存资源,因此你不必担心资源文件的错误url导入。
首页 index.php:
这是一个可以获取网页的html代码以及css,js,font和img资源的小工具,主要用来快速获取模板。如果你来不及设计UI或者看到不错的模板,则可以使用这个工具来抓取网页和提取资源文件。提取的内容会按相对路径来保存资源,因此你不必担心资源文件的错误url导入。
首页 index.php:
抓取页面代码 grab.php:
1 | <?PHP |
保存css,js,img等资源的页面 save.php:
1 | <?PHP |
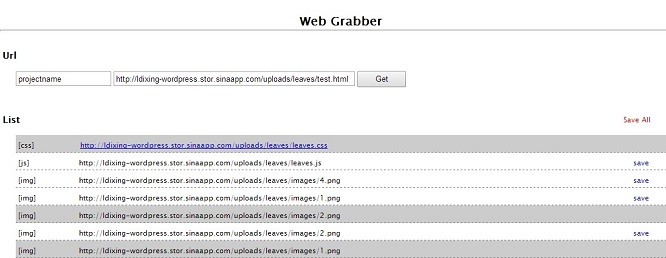
使用方法:
1. 打开index页,输入项目名和要抓取的网址,网址必须是文件名结尾,如index.html;
2. 点Get按钮,得到当前页面所有的css,js,img等资源列表;
3. 点击css链接会获取css文件中的背景资源图片,附加在列表后头;
4. 点击Save All即可保存列表中所有的文件,并按相对路径生成;
5. 如果网页上有http远程文件,将会直接保存在http文件夹下;
6. Get和Save有时会失败,没关系重试几次即可。
效果图:
PHP抓取静态页面源码及资源并保存

